JavaでBasicライク言語のインタプリタ実装 #2 構文解析編-1
今日書くこと
今日は昨日から続いている、「JavaでBasicライクな言語のインタプリタを実装する」の第2回目の記事です。 昨日の記事は
こちらになります。
今日は構文解析の部分を解説&実装していこうと思います。
構文解析
構文解析とは?
構文解析とは、字句の並びから、プログラム言語の文法(Syntax)と照らし合わせAST(抽象構文木)を作ることです。 よくあるシンタックスエラー(かっこの対がおかしいとか、for文の使い方が間違ってる)などはこの段階で判明するわけですね。
具体的には
a = 5 DO UNTIL a < 1 PRINT "HELLO" a = a -1 LOOP END
このようなプログラムを読み込んで、

のような構文木を構築することです。
Do untilのブロック内に関数実行と代入文があり、代入文はaにa-1の結果を入れる。
と言うような意味が発生するようになります。
字句解析の時点では、それぞれどんな字句かだけだったのが、字句の並びと文法規則からそれぞれ意味を持つようになります。
文法
ボスが文法を示してくれるのでそれを参考にしましょう。
https://service.cloud.teu.ac.jp/lecture/CSF/ktago/lecture_prog/syntax.txt
BNF記法で書いてあるやつですね。 これとにらめっこしながら作ります。
構文解析部分攻略方
ファースト集合とかフォロー集合とか、終端記号とか非終端記号とかの単語をちゃんと理解しましょう。 kmd先生の講義を取ればちゃんと教えてくれる上に、構文解析表とかも書けるようになります。
ボスもなんだかんだそれっぽいことを教えてくれるけどね。
この部分は基本的にひたすら実装なので流れをつかんで時間があるときにやってください。 式の部分は明日解説しますが、そこだけちょっと面倒。
実装
実装方針
非終端要素についてクラスを1つ1つ作ります。 それぞれのクラスはNodeクラスを継承するようにします。
Nodeクラスは抽象クラスとしparse()の関数実装を強制します。
Nodeクラスを継承した非終端要素のクラスでisMatch()とparse()を実装します。
isMatchは、与えられた字句が、その非終端要素のファースト集合に含まれるかどうかを判定し、含まれるならば自身をインスタンス化して返します。 また、今回の文法はLL2である(2個先まで読まないとどの文法規則を適用すればいいか確定しない cf 代入文(NAME => EQ)と関数呼び出し(NAME => LP))ので そういう重複がありえる非終端要素の場合は確定させるまで読んで返します。
parseは、字句を読み進め、自分の下の要素を構築したりします。
コードで示した方が早そうなので書いていきます。
すべての実装は、
にあります。 syntax_nodeパッケージが今回の非終端要素のクラス群が入っているところです。
それでは。
Node.java
大本のクラスです。 すべての非終端要素のクラスはこれを継承させます。
/** * 全構文要素の親クラス. * 構文木の非終端要素 */ public abstract class Node { /** * Nodeのタイプ. */ public final NodeType type; /** * 実行環境. * 変数テーブル. 関数テーブル. 字句解析器等. */ public final Environment env; public Node(NodeType type, Environment env) { this.type = type; this.env = env; } public NodeType getType() { return type; } /** * 文法解析メソッド * @return 構文にマッチしないならfalse */ public abstract boolean parse(); // toStringの実装を強制 public abstract String toString(); /** * 次のLexicalUnitを見る Utilメソッド */ protected LexicalUnit peekLexicalUnit() { LexicalUnit unit = env.getInput().get(); env.getInput().unget(unit); return unit; } /** * 次の字句タイプを見て期待した字句と一致していればその字句を読み飛ばすUtilメソッド * NLとかLOOPとかのチェックしないといけないけど無視する字句に使う * * もし次に現れた字句が期待した物と一致しないのであればfalseを返す * * @param expectType 複数指定した場合は指定した順番でチェックしつつ読み飛ばす * @return 期待した字句と一致しない場合false */ protected boolean skipExpectNode(LexicalType... expectType) { for (LexicalType expect : expectType) { if (peekLexicalUnit().getType() == expect) { env.getInput().get(); continue; } return false; } return true; } }
ポイントとしては、Nodeクラスにある程度のUtilメソッドを含めておくと楽です。
例えばpeekLecicalUnitは単に次の字句を見ることができます。
skipExpcetNodeは字句をチェックしつつ読み流すときに使います。 この処理はなんども後で出てくるので一括してここで定義しておくといいです。
ProgramNode.java
Nodeを継承した、構文木のトップ要素のProgramNodeは以下のように書けます
/** * <program> ::= * <stmt_list> * */ public class ProgramNode extends Node { // StmtListNode private Node child; public ProgramNode(NodeType type, Environment env) { super(type, env); } static FirstCollection fc = new FirstCollection( StmtListNode.fc, BlockNode.fc ); public static Node isMatch(Environment env, LexicalUnit first) { // LexicalUnit first が First集合に含まれる字句か判断する. if (fc.contains(first)) { return new ProgramNode(NodeType.PROGRAM, env); } return null; } @Override public boolean parse() { NextNodeList nextNodeList = new NextNodeList(StmtListNode.class); Node chiled = nextNodeList.nextNode(env, peekLexicalUnit()); if (chiled != null) { this.child = chiled; return chiled.parse(); } return false; } @Override public String toString() { return child.toString(); } }
isMatchではProgramノードのファースト集合に含まれるかを判定させます。 ここでProgramノードのファースト集合はStmtListNodeのファースト集合とBlockNodeのファースト集合の和集合であるということに気づくとコードがきれいになります。
この和集合を扱うために以下のようなことをします。
/** * First集合のコレクション. * */ public class FirstCollection { List<LexicalType> firstListUnit; public FirstCollection(LexicalType... firstTypes) { this.firstListUnit = Arrays.asList(firstTypes); } public FirstCollection(FirstCollection... firstCollections) { this.firstListUnit = new ArrayList<>(); for (FirstCollection firstCollection : firstCollections) { firstListUnit.addAll(firstCollection.firstListUnit); } } public boolean contains(LexicalUnit unit) { LexicalType type = unit.getType(); return firstListUnit.contains(type); } }
このようなFirst集合を合わせたりして扱うことができるクラスを用意しておき、上位のfirst集合は直接字句を書かず、子のファースト集合の和集合として定義するときれいです。
static FirstCollection fc = new FirstCollection( StmtListNode.fc, BlockNode.fc );
こんな感じでね。
parse()は子のisMatch(stmtlistのisMatch)を呼び、自身のフィールドに子のインスタンスを保持するようにします。 こうして、ProgramがフィールドにStmtListのインスタンスを持ち、StmtListがフィールドにAssignStmtやLoopBlockのインスタンスを持ち。。。と順々につなげていくことでリンクするように、構文木が表現できます。
またコードをさくっと終わらせるために、 一々isMatchを呼び出して確定させる等の処理は面倒(子に持ちうるのが複数の非終端要素の場合があり得て、何個もisMatchを呼ばなきゃいけない)なので、
/** * 子になりうるNodeのリスト. * * first集合の字句を投げて、子のnodeのインスタンスが得られるUtilクラス * * 必須要件. * 登録されたNodeにはisMatchが静的メソッドとして実装されている */ public class NextNodeList extends ArrayList<Class<? extends Node>> { public NextNodeList(Class<? extends Node>... nextNodes) { addAll(Arrays.asList(nextNodes)); } /** * 次の一致するノードを探し出す. */ public Node nextNode(Environment env, LexicalUnit unit) { Iterator<Class<? extends Node>> i = iterator(); while (i.hasNext()) { Method isMatch; try { isMatch = i.next().getMethod("isMatch", Environment.class, LexicalUnit.class); Object res = isMatch.invoke(null, env, unit); if (res != null) { return (Node) res; } } catch (NoSuchMethodException | SecurityException | IllegalAccessException | IllegalArgumentException | InvocationTargetException ex) { // programming error ex.printStackTrace(); } } return null; } }
こんなちょっとごにょってるクラスを作ってしまい、
NextNodeList nextNodeList = new NextNodeList(StmtListNode.class); Node chiled = nextNodeList.nextNode(env, peekLexicalUnit());
こんな感じで一気に処理すればisMatchをNextNodeListに登録したクラス全部に試行して、確定した子ノードのインスタンスを返してくれるnextNodeメソッドが使えるようになります。
リフレクションしたのは反則感があるけど。
StmtListを作ったら、似たような感じでどんどん構文を下に向かって作っていきます。(ExprNode以外はノリでいけます)
StmtListNode.java
/** * <stmt_list> ::= * <stmt> * | <stmt_list> <NL> <stmt> * | <block> * | <block> <stmt_list> * */ public class StmtListNode extends Node { private List<Node> childNodes = new ArrayList<>(); public StmtListNode(NodeType type, Environment env) { super(type, env); } static FirstCollection fc = new FirstCollection( StmtNode.fc, BlockNode.fc ); public static Node isMatch(Environment env, LexicalUnit first) { if (fc.contains(first)) { return new StmtListNode(NodeType.STMT_LIST, env); } return null; } @Override public boolean parse() { while (true) { // NLを読み飛ばす if (peekLexicalUnit().getType() == LexicalType.NL) { env.getInput().get(); continue; } NextNodeList nextNodeList = new NextNodeList(StmtNode.class, BlockNode.class); Node chiled = nextNodeList.nextNode(env, peekLexicalUnit()); if (chiled != null) { if (!chiled.parse()) { return false; } // Stmtの後にはNLが存在する if (chiled instanceof StmtNode) { env.getInput().get(); } childNodes.add(chiled); continue; } return true; } } @Override public String toString() { return childNodes .stream() .map(Node::toString) .collect(Collectors.joining(";")); } }
StmtListも同じように、ファースト集合はStmtNodeとBlockNodeのファースト集合の和集合になるので、ProgramNodeと同じように定義します。 parseもStmtListの下はStmtNodeかBlockNodeなので、どちらか調べてさらにそれぞれparseしていきます。 子のparseに成功したら、自身のフィールドで子ノードとして保持しておきます。
LoopBlockNode.java
だんだん下のほうの非終端要素になると、終端要素をチェックしたり色々が始まります。 LOOPとかはその最たる例。 DO や UNTILとかがちゃんと正しい順番で入ってるかチェックしないとだめ
/** * <block> ::= * | <WHILE> <cond> <NL> <stmt_list> <WEND> <NL> * | <DO> <WHILE> <cond> <NL> <stmt_list> <LOOP> <NL> * | <DO> <UNTIL> <cond> <NL> <stmt_list> <LOOP> <NL> * | <DO> <NL> <stmt_list> <LOOP> <WHILE> <cond> <NL> * | <DO> <NL> <stmt_list> <LOOP> <UNTIL> <cond> <NL> */ public class LoopBlockNode extends Node { /** * Do While 文 つまり1度は走る文かどうか */ private boolean isDo; /** * While文ならtrue Until文ならfalse */ private boolean isWhile; /** * ループ実行条件ノード */ private CondNode condNode; /** * ループブロック本体 */ private StmtListNode stmtListNode; public LoopBlockNode(NodeType type, Environment env) { super(type, env); } static FirstCollection fc = new FirstCollection( LexicalType.WHILE, LexicalType.DO ); public static Node isMatch(Environment env, LexicalUnit first) { if (fc.contains(first)) { return new LoopBlockNode(NodeType.LOOP_BLOCK, env); } return null; } @Override public boolean parse() { LexicalUnit first = env.getInput().get(); // DO if (first.getType() == LexicalType.DO) { return doParse(); } // WHILE if (first.getType() == LexicalType.WHILE) { return whileParse(); } return false; } /** * Do文を解析 * @return */ private boolean doParse() { isDo = true; LexicalUnit next = env.getInput().get(); switch (next.getType()) { case WHILE: case UNTIL: // do - (while or until) - cond -nl -stmtlist - loop - nl untilOrWhileHandl(next); if (!condHandl()) { return false; } if (!skipExpectNode(LexicalType.NL)) { return false; } if (!stmtListHandl()) { return false; } if (!skipExpectNode(LexicalType.LOOP, LexicalType.NL)) { return false; } return true; case NL: // do - nl - stmtlist - loop - (while or until) - cond -nl if (!stmtListHandl()) { return false; } if (!skipExpectNode(LexicalType.LOOP)) { return false; } if (!untilOrWhileHandl(env.getInput().get())) { return false; } if (!condHandl()) { return false; } if (!skipExpectNode(LexicalType.NL)) { return false; } return true; default: return false; } } /** * While文を解析 * @return */ private boolean whileParse() { isDo = false; isWhile = true; // while -> cond -> nl -> stmtlist -> loop -> nl if (!condHandl()) { return false; } if (!skipExpectNode(LexicalType.NL)) { return false; } if (!stmtListHandl()) { return false; } if (!skipExpectNode(LexicalType.LOOP, LexicalType.NL)) { return false; } return true; } /** * Loopブロックの条件式部分を解析 * @return SyntaxErrorならfalse */ private boolean condHandl() { condNode = (CondNode) CondNode.isMatch(env, peekLexicalUnit()); if (condNode == null || !condNode.parse()) { return false; } return true; } /** * LoopブロックのStmtList部分を解析 * @return SyntaxErrorならfalse */ private boolean stmtListHandl() { stmtListNode = (StmtListNode) StmtListNode.isMatch(env, peekLexicalUnit()); if (stmtListNode == null || !stmtListNode.parse()) { return false; } return true; } /** * Until文なのかWhile文なのか調べてインスタンス変数に情報格納 * @param unit Until or Whileの LexicalUnit */ private boolean untilOrWhileHandl(LexicalUnit unit) { switch (unit.getType()) { case WHILE: isWhile = true; return true; case UNTIL: isWhile = false; return true; } return false; } @Override public String toString() { return "LOOP[" + condNode + "[" + stmtListNode + "]]"; } }
こんな感じでいけます。 そろそろ長くなって辛くなってきた。 LOOPのチェックとかがちゃんとできればあとは流れでほかのNodeも作れるでしょ。
さいご
ファースト集合とか、構文解析表とか知ってれば、あとは構文木をどんな感じに構成すればいいか(フィールドに子を持たせる)を思いつけばコードにできますね。
ここはひたすら実装が必要なのでだるいところ。 BNF記法流し込んだら構文木自動構築みたいなことしないかぎり実装はそんな面倒じゃない。
明日は構文木を組み上げるうえで一番面倒くさい式の解析の部分を書こうと思います。
JavaでBasicライク言語のインタプリタ実装 #1 字句解析編
これから書く記事の概要
実践的プログラミング
弊学では3年次にJavaでBasicライク言語のインタプリタを実装する、「実践的プログラミング」という講義があります。
弊研のボスがやっている、プログラミング力を一気に上げる講義です。 弊研究室に所属した場合、この講義の単位の修得が要求されます。
よく単位とれないと進級できないとかいう嘘を流してる人が居ますが、あれは嘘です。 履修も絶対しなきゃいけないわけじゃないです。 進級条件にかかってない適当な枠の講義をの単位をネタにそれで進級させないとかして、ゴネたら面倒になるでしょ。 過去に単位取らずに卒業した人も居ます。
ただ、別に面倒なわけじゃないし&プログラム将来書くなら役に立つこと間違いなしの講義なので、積極的に受けないって方針は採らなくていいと思います。
講義の扱い的には、「実質強制参加の会社の忘年会」的な扱いだと思って下さい。 わたしはまだ忘年会未経験なので本当に合ってるかはわかりませんけど。
この講義、なんか毎度よくわからんと言い始める人がいっぱい居ます。 今年も研究室で騒いでいる人がいっぱい居るので、ほら簡単やろ?って証明するために去年私が作ったコードをひたすら載せつつ、解説します。
成果物
最終的にこんなのが作れますよ。
PRINT "x^2 -8x -16"
a = 1
b = -8
c = -16
def = SQRT((b * b) - (4 * a * c))
res1 = ( -b - def) / 2 * a
res2 = ( -b + def) / 2 * a
PRINT "x = (" + res1 + "," + res2 + ")"
Syntax parsed --- PRINT[x^2 -8x -16];a[1];b[SUB[8]];c[SUB[16]];def[SQRT[SUB[MUL[b,b],MUL[MUL[4,a],c]]]];res1[MUL[DIV[SUB[SUB[b],def],2],a]];res2[MUL[DIV[ADD[SUB[b],def],2],a]];PRINT[ADD[ADD[ADD[ADD[x = (,res1],,],res2],)]] ----------------- -------run!------ x^2 -8x -16 x = (-1.6568542494923806,9.65685424949238)
連載目次
1日で全部書くと長くなるので何日かに分けて書いて公開していこうと思います。
講義の流れとして 字句解析=>構文解析=>実行系 という形でプログラムを作っていくので、それに添った形で書いていきます。
というスケジュールで行きます。 書きためしてコミケ中のネタ用に数日増やすかもしれません。
さて書いていきます。 今日は講義攻略のおすすめ方針と、第一回のレポートのネタになる字句解析部分のプログラム解説をします。
講義攻略方針
この講義の難易度は、3年次に並行して走ってる kmd先生の「形式言語とオートマトン」 という講義を取ったかどうかで天と地の差が生まれます。 基本的にプログラミング言語の構成を知っていればインタプリタの作り方は分かるので、コンパイラの作り方を説明するkmd先生の講義を取り概略をつかめば何をすれば良いか全部分かります。
この講義を取るか、コンパイラの作り方を一度どっかで勉強したことがあれば特に困ることはありません。
逆にしていないとよくわからなくなります。 ボスの説明を頑張って聞いて作りましょう。
字句解析
字句解析とは
字句解析とは素のプログラムを読み込んで、書かれている単語のまとまりを作り、1つ1つにどういう意味があるのか判明させる処理です。
具体的には、
a = 1
という素のプログラムから a , = , 1 と分割し、それぞれa(変数名)、=(演算子 Equal)、1(値,整数, 1) というように意味をラベル付けしていきます。
要求される動作
レポートではこれを満たす必要があります。
以下の入力を受け取り
a = 50.1 DO UNTIL a < 1 PRINT "Hello" a = a - 10 LOOP END
以下の出力を行うこと
NAME: a EQ DOUBLEVAL: 50.1 NL DO UNTIL NAME: a LT INTVAL: 1 NL NAME: PRINT LITERAL: Hello NL NAME: a EQ NAME: a SUB INTVAL: 10 NL LOOP NL END EOF
字句解析部分の攻略方
kmd先生の講義を取っていれば、字句解析は正規表現と深い関わりがあり、(普通の)正規表現は有限オートマトンで処理できるーということを知ることが出来ます。 取ってない人も今知りましたね?
字句はすべて正規表現で表現が可能です。
- WORD(a, DO, WHILE, END) =>
^[a-zA-Z]\\w* - LITERAL("hogehgoe") =>
^\"[^\"]*\"? - NUMBER (4423, 4.2) =>
[0-9.]+ - 一字のOPERATER( =, + , - +=) =>
[\\.\n\\+\\-\\*\\/\\)\\(,]
こんな感じですね。(全部は網羅してません&複数の字句がマッチする場合あり)
読み込んだプログラムをの状態遷移図を作成し、最適化を施し、その状態遷移を実現するようにJavaのコードを書けば字句判定が完成します。 これがお作法っぽい作り方です。
ただし、状態遷移図からJavaのコードをIFやループを使って生み出すと面倒なので、 字句を正規表現で表した後、Javaの標準ライブラリに正規表現処理をさせてやればいいです。
ここで正規表現処理エンジンを作らせたるよう強制しないのがボスの優しさですね。 正規表現エンジンも作ったりした方が良いと思うんだけどなぁ。
アルゴリズム
1つの字句は以下の手順で得られる.
- 字句の始まりとなり得る文字(英数字, 記号, 改行文字) を得る
- その文字が, 変数or 予約語, 数字, リテラル, 演算子のどれに該当するのか判断する
- 対応する種別に応じて字句に許容されない文字が現れるまでソースを読み, 初めの字から許容されない 文字が現れるまでの文字をつなげた物を1字句の内容とする
- 得られた文字列に対して実際にどのような字句なのか, 予約語なのか, どの演算子なのか等をより細かく 見て字句を確定し出力する
ソースコードを読みこみながら、上記手順を繰り返すことでソースコードから字句を1つずつ取り出すことが出来ます。
コードの書きやすさ的には、これを実装に移すのが一番さっくりいくと思います。 実装にJava力をちょっと必要としますが。。。。
実装
すべての実装は
にあります。lexical_parserパッケージ及びcoreパッケージが字句解析に関連した部分です。
メインエントリポイント
public class Main { public static void main(String[] args) throws Exception { LexicalAnalyzer analyzer = new LexicalAnalyzerImpl("test1.bas"); LexicalUnit unit; for (unit = analyzer.get(); unit.type != LexicalType.EOF; unit = analyzer.get()) { System.out.println(unit); } System.out.println(unit); } }
字句を切り出しLexicalUnit作る処理部分
アルゴリズムに基づいてまず大まかに分けるようにします。 ここを正規表現でやるのがコード簡略化のこつです。
public enum TokenType { NUMBER("[0-9.]+"), // 0-9から始まりdotを含んで連続する(笑) WORD("^[a-zA-Z]\\w*"), // A-Za-zから始まって単語構成文字が連続する LITERAL("^\"[^\"]*\"?"), // "から始まりε "があったらそれでおしまい.(エスケープシーケンス) SINGLE_OPERATOR("[\\.\n\\+\\-\\*\\/\\)\\(,]"), // 1文字で構成される字句 MULTY_OPERATOR("[><=]|=[><]|[><]=|<>"); // 複数文字で構成されうる演算子 > < = => >= =< // <= <> private final Pattern pattern; private TokenType(String regx) { this.pattern = Pattern.compile(regx); } public boolean isMatch(String test) { return pattern.matcher(test).matches(); } }
定義的に正規表現を埋め込んだこのEnumを使って、一気に処理します。
下のクラスは ソースコード(テキスト)を1文字ずつよんで、なんか意味ある始めの一字(EOFやスペースではなく次のTokenを構成する1字) まで読み、上のEnumのマッチを使ってどれか確定させ、tokenにします。
/** * Streamを読んでTokenに切り出すクラス. * テキストデータを1文字ずつよんでTokenに分割 */ public class TokenParser { /** * テキストデータ読み込みReader */ private Reader reader; private boolean readerIsEOF = false; public TokenParser(Reader reader) { super(); this.reader = reader; } /** * 字句確定のためにreadしちゃった次の字句を持っておく */ private String nextTokenBuff = ""; /** * 次のTokenを得ます. */ public Token get() { if (readerIsEOF == true) { return null; } // EOFやスペースではなく次のTokenを構成する1字を得る String tokenFirstStr = normalizeStr(nextTokenBuff); if (!readerIsEOF && tokenFirstStr.isEmpty()) { tokenFirstStr += readNextStr(); } // トークン始まりの字にマッチするtokenTypeを得る TokenType tokenType = getMatchTokenType(tokenFirstStr); // マッチが外れ、違う字句になるまで読みTokenの値を得る String tokenVal = tokenFirstStr; while (!readerIsEOF && tokenType.isMatch(tokenVal)) { tokenVal += readNext(); } // マッチ外れたときに入ったアルファベットは次の字句の可能性ありありなので保持 // cf. a= はa=のときにマッチが外れるが=はそれ自体次の字句 this.nextTokenBuff = String.valueOf(tokenVal.charAt(tokenVal.length() - 1)); // 出力するトークンからは次の字句の文字は消す tokenVal = tokenVal.substring(0, tokenVal.length() - 1); return new Token(tokenType, tokenVal); } /** * TokenTypeからTokenTypeのパラメータに一致するやつ探し出す. * <始めの1字がどのトークンタイプか判別する.> * @param tokenFirstStr Tokenの初めの1字 */ private TokenType getMatchTokenType(String tokenFirstStr) { Optional<TokenType> tokenTypeOpt = EnumSet.allOf(TokenType.class) .stream() .filter(t -> t.isMatch(tokenFirstStr)) .findFirst(); return tokenTypeOpt.get(); } /** * 文字を標準化 * CRをスペースに (LFだけにする) * タブはスペースに * 最後にスペースは消し去ります */ private String normalizeStr(String str) { return str .replaceAll("\t", " ") .replace('\r', ' ') .replaceAll(" ", ""); } /** * 次の"字"を1つ読み返すよ * (スペースとかは無視されるよ) */ private String readNextStr() { String tmp = ""; while (tmp.isEmpty() && !readerIsEOF) { char c = readNext(); tmp += c; tmp = normalizeStr(tmp); } return tmp; } /** * ストリームから1"文字"読みます. (スペースとかが返ってくるよ) * もしEOFだったらisEOFをtrueにして0を返します... */ private char readNext() { if (this.readerIsEOF == true) { return 0; } int ci = 0; try { ci = reader.read(); } catch (IOException ex) { ex.printStackTrace(); } // EOF if (ci == -1) { this.readerIsEOF = true; try { reader.close(); } catch (IOException ex) { ex.printStackTrace(); } return 0; } return (char) ci; } }
これで1字句分がTokenインスタンスとして切り出せます。 EnumのSetに対してストリームAPIを利用し一気にマッチ処理をさせるのがポイントです。
とれたTokenクラスは
/** * Token * ソースコードから切り出したトークン * * SorceCode -> Token -> LexcalUnit * @author namaz * */ public class Token { private TokenType type; private String value; Token(TokenType type, String value) { this.type = type; this.value = value; } public TokenType getType() { return type; } public String getValue() { return value; } /** * このトークンをタイプに応じて解析し, * より詳しく細分化されたLexicalUnitへ変換します. */ public LexicalUnit parseLexicalUnit() { // それぞれのトークン種別に応じて解析. LexicalUnit res = null; switch (type) { case NUMBER: res = parseNumberToken(); break; case WORD: res = parseWordToken(); break; case LITERAL: res = parseLiteralToken(); break; case SINGLE_OPERATOR: case MULTY_OPERATOR: res = parseOperatorToken(); break; } return res; } private LexicalUnit parseWordToken() { // 予約語の抽出. Optional<ReservedWord> reservedWordOpt = EnumSet.allOf(ReservedWord.class) .stream() .filter(t -> t.isMatch(value)) .findFirst(); if (reservedWordOpt.isPresent()) { // 予約語とマッチした. LexicalType type = reservedWordOpt.get().getType(); return new LexicalUnit(type); } // 予約語とマッチしない 単語 -> 変数. return new LexicalUnit(LexicalType.NAME, new ValueImpl(value)); } private LexicalUnit parseNumberToken() { // Double if (value.contains(".")) { return new LexicalUnit(LexicalType.DOUBLEVAL, new ValueImpl(value)); } // Intval return new LexicalUnit(LexicalType.INTVAL, new ValueImpl(value)); // TODO: もっと精巧な.とかの処理. 指数部とか + - とかの符号もね } private LexicalUnit parseLiteralToken() { // ”を消す String literalVal = value.replaceAll("\"", ""); return new LexicalUnit(LexicalType.LITERAL, new ValueImpl(literalVal)); } private LexicalUnit parseOperatorToken() { // オペレーター種別の識別. Optional<Operator> operatorOpt = EnumSet.allOf(Operator.class) .stream() .filter(t -> t.isMatch(value)) .findFirst(); if (operatorOpt.isPresent()) { // 値に該当するオペレーターが存在した LexicalType type = operatorOpt.get().getType(); return new LexicalUnit(type); } // 該当しないはずがない return null; } }
こんな感じで、より詳細に調べてLexicalUnitを作ります。
LexicalAnalyzerImpl
こうしてToken => LexicalUnitとすることで, ボスが渡してくるLexicalAnalyerImplは
public class LexicalAnalyzerImpl implements LexicalAnalyzer { private TokenParser tokenParser; public LexicalAnalyzerImpl(String filePath) throws Exception { tokenParser = new TokenParser(new FileReader(filePath)); } @Override public LexicalUnit get() { Token nextToken = tokenParser.get(); // TokenをLexicalUnitへ if (nextToken == null) { // nullが返ってきたらEOF return new LexicalUnit(LexicalType.EOF); } return nextToken.parseLexicalUnit(); } }
こんな風に書けます。
予約語とか演算子のLexicalTypeとの関連付け判定
文字から予約語や、記号からどの記号のLexicalTypeになるか?とかいう部分については 下のように、全ての演算子を網羅したEnumを用意しておき。。。
/** * すべての演算子の列挙 及びLexcalTypeとの関連付け * 一時決まりの字句とかもここだよ. */ public enum Operator { EQ(LexicalType.EQ, "="), LT(LexicalType.LT, "<"), GT(LexicalType.GT, ">"), LE(LexicalType.LE, "<=", "=<"), GE(LexicalType.GE, ">=", "=>"), NE(LexicalType.NE, "<>"), ADD(LexicalType.ADD, "+"), SUB(LexicalType.SUB, "-"), MUL(LexicalType.MUL, "*"), DIV(LexicalType.DIV, "/"), LP(LexicalType.LP, ")"), RP(LexicalType.RP, "("), COMMA(LexicalType.COMMA, ","), NL(LexicalType.NL, "\n"), DOT(LexicalType.DOT, "."); private final String[] vals; private final LexicalType type; private Operator(LexicalType type, String... vals) { // >= => とかが同じ意味なので配列にしときます. this.vals = vals; this.type = type; } /** * 与えられた文字列と字句の決まり字が一致するかどうか */ public boolean isMatch(String test) { for (String string : vals) { if (string.equals(test)) { return true; } } return false; } public LexicalType getType() { return type; } }
この全ての定義を見て、確定させる処理を
// オペレーター種別の識別. Optional<Operator> operatorOpt = EnumSet.allOf(Operator.class) .stream() .filter(t -> t.isMatch(”Tokenの文字”)) .findFirst(); if (operatorOpt.isPresent()) { // 値に該当するオペレーターが存在した LexicalType type = operatorOpt.get().getType(); return new LexicalUnit(type); }
こんな感じで一気に行うのが楽しい。 全部Mapに突っ込んで引くという方法もあるけどね。
valueimpl
これを作れーってボスが言いますが まぁ
public class ValueImpl implements Value { private ValueType type; // 全部stringで持っとけ・・・ private String val; public ValueImpl(String s) { type = ValueType.STRING; val = s; } public ValueImpl(int i) { type = ValueType.INTEGER; val = i + ""; } public ValueImpl(double d) { type = ValueType.DOUBLE; val = d + ""; } public ValueImpl(boolean b) { type = ValueType.BOOL; val = b + ""; } @Override public String getSValue() { return val; } @Override public int getIValue() { return Integer.parseInt(val); } @Override public double getDValue() { return Double.parseDouble(val); } @Override public boolean getBValue() { return Boolean.parseBoolean(val); } @Override public ValueType getType() { return type; } }
こんなんで良いでしょう。 値はString形式で常に持っておくとわざわざ面倒な処理を書かなくてもいい。
字句解析まとめ
字句の正規表現が考えられさえすれば、あとはいろいろな方法でコードにできるでしょう。 何も難しいことなし。
一年経った今になって考えると、もっとざばっと単純明快に処理する方法を思いついていて、あーーーってなりながら今日書きました。 LexicalTypeってEnumを渡されるので、そこに手を入れて、すべて正規表現を書き、他の字句と一致した場合の優先度とかも書けば、LexicalTypeを一回見るだけで特定が可能じゃんって。。。 無駄に2段階挟んだりしてやらなくてもよかった。
明日
明日は、絶賛レポート締め切りが近いらしい、構文解析部分の実装を書いていこうと思います。 一気に構文解析部分を書くのは辛いので、式部分以外を明日は書こうかな。 それでは。
環境破壊した話と今年のアドベントカレンダー個人まとめ
きょうやったこと
最重要案件をすっぽかす
卒論バトルをボスとしようと思って大学に行ったのです。
大学着いた時点では寝ぼけていて、ボスが「それじゃもういくからねー。」っていうのに「はーい。」って返事してた。 ボスに7kくらい立て替えて貰うはずだったのにそれも忘れてた。
お金立て替えてもらうの忘れた。。。。明日も大学行かなあかんくなった
— namazu (@namazu510) 2017年12月25日
結局明日も行かなければならなくなった。 だるいにゃぁ。。。。
環境破壊神の影響を受けた
某所のサービスを復旧させてたらNginxが起動しなかった。 なんかライブラリがぶっ壊れたっぽい。 再度プロビジョニングしてやりました。 Ansibleでぜんぶやってるとこういうのに対して、1からやり直すっていう作戦が気負いなく選べていいです。
Nginxは結構すぐ治りました。
そのあと、なんか研究室k8sのワーカーノードGTX460*2SLI構成の古い子が、ICMP応答しないので、見に行きました。
死んでました。 ゴミでした。 古いマシンなので11階から地面に向けて投げ捨てようかと思いました。
OS再インストールしようとしたらPXEからインストール出来ないし、インストーラの画面も出てこなくなったので、オタク部屋でアニソン大音量で流してごろごろしてました。
俺も環境破壊神になってしまったかーと最悪な気分でした。
何もかもうまく動かんしカタケンに飛行機つっこんでぜんぶおしゃかになれって気分
— namazu (@namazu510) 2017年12月25日
結局、カーネルのリストを全部試したら上から4番目のカーネルで起動したっぽい(画面は出ないけどSSH接続できる)
グラボは使えなくなったのでcut-terにあげました。 遊ぶらしいです。 ゴミの460でも2枚あればそこそこ働けると思います。 環境破壊神に貢ぎ物をしたので、これでもうなんかこわれたにゃぁ。。。ってならないで欲しいです。
さっきkube-06(1080Tiの刺さった新品ちゃん)のICMP応答が帰ってこなくなった事を知りました。 死にたいです。
アドベントカレンダー終日
もう25日かーという気分です。 Twitterや渋にはコミケのお品書きや表紙イラストがいっぱい流れてますね。 さっきTwitterでとってもエロ可愛いにゃんこちゃんの表紙イラストが流れてきて最高になりました。
今年書いたアドベントカレンダーでも振り返ってみようと思います。
参加したのは以下。
- 研究室
- 同期
- 大学のなんかやってたやつ
この辺に書きました。
書いた記事は、こんなところです。
最後の方日和った感がありますね。 まぁ卒論バトルしてたりいろいろで調子が上手くいってなかったので、仕方ないところあるけれど。。。
来年はもっと強い記事書きたい
社会人になるので1年修行した成果が現れるような記事を書きたいですね。
どうでもいいはなし
なんか色々ぐうたら動きすぎて成果が生まれていない気がします。 体力がないんすよね。 なんか。 最近物理で動かないと進捗が出ない案件がある程度あり、それの対応に体力がないせいで動くのを躊躇し、結局ぐうたらでgdgdということをしてる。
性格的に、ある程度上手くいかないとフラストレーションが溜まってきて、進捗が生まれにくい行動に走るのでよくない。 カタケンと研Aの間を特になにも感じずさらっと移動できるくらいの体力と精神力と肉体が欲しいです。
筋トレとかしたほうがいいんすかね? しませんけど。
なまずの一年を振り返る。
はじめに
この記事は所属する研究室のアドベントカレンダー23日目の記事です
このアドベントカレンダーも既に23日目と終わりに近くなってきました。 始めはどうなるか分からない感じでしたが、皆ちゃんと埋めてくれて繋がっていってよかった。
今日は当初SQLパズルを解いたりしようとおもいましたが、そういえば振り返り記事とか書いてないな(なんか面倒になった)と思ったので、
主題変更しなまずの一年を振り返る誰得な記事を書こうと思います。
今年のアドベントカレンダーで一番誰得な記事を投稿することになってしまいそう。だが気にしない。
Githubの草
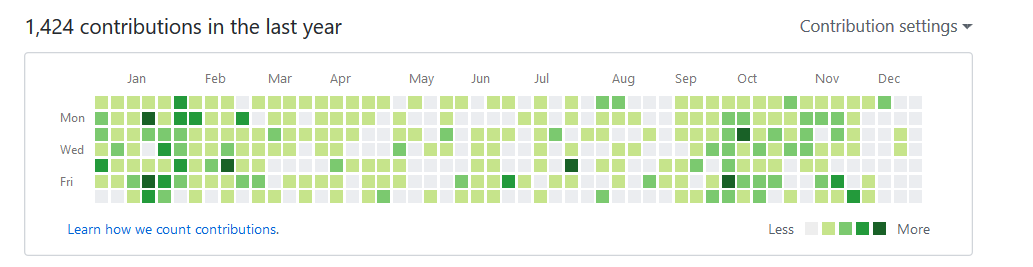
Githubの草を見てみるといつコード書いていたか分かる。 コード書いてないときはGithubにプッシュしない作業をしていたとき。
1月
たぶんメインは就活したりだった。 終盤に近づいてきていて、内定貰ったり、選考辞退したりしていた。
研究室のプロジェクトのWebサイトを作ったり、実験でフロントを書いたり等 一番フロントエンドをしていた時期だった気がする。
最近は全くもってフロントを書いていないのでよくない。
2月
就活していた。 いろいろなエンジニアにあえて、モチベーションが大分高まった時期だった気がする。 インターンで長崎に行ったり、名古屋に面接に行ったりと色々とアクティブに動いていた時期かも知れない。
フロントのモチベが高く、いろいろ触ったり、変な物を量産したりしていた。
3月
就活が終わった。 大学の講義とかとの兼ね合いもあって最終を後ろに伸ばして貰ったりしていたので、決着が付くのは遅くなった。
就活中に知り合った企業にインターンをさせてもらったりした
4月
春休みを取ってた。 実家に帰ってのんびりしていた気がする。
Kubernetesとかいうのを研究室にセットアップし始めたり、 Dockerについて色々と使うようになった。
今年一番の馬鹿発言
「なんでNginxでNFSがリバースプロキシできないんですか?」
という発言をしたのがこの時期だったきがする。 今になって思うとこいつ馬鹿すぎだろと思う。
基礎知識がなさ過ぎてTCP/IPの基礎をお勉強しなおしたりしていた。
インターンで使ってるのをみてSwaggerなるものに触れたら、なんか楽しくて、いろいろなところのドキュメントをSwaggerで書き出したりしていた。 これはいいものだって。
某所のポータルの構造とかもこの時期に調べて全部纏めた。 ドキュメントが無い状態だったので、サーバに入って色々調べるなどしていた。 インフラに傾いた一年の原因を作ったのがこの時期だったとおもう。
この時期はまだ私はポータルの闇を払うつもりで色々としていた。
研究室が分裂して、いろいろな人が居なくなった。
5月
k8sを触っていた。 この時期で、今はなぜ始めたのか忘れたが、 最終的に卒論ネタになる、ソフトウェア開発を始めた。
なんでこれを始めたのか全くもって思い出せない。
でもこの時期は、まだポータルで卒論を書くつもりだったはず。
6月
前述の卒論ネタのソフト。 Heroku擬き をがっつり開発していた。 この時期からよく大学にお泊まりするようになった気がする。
切っ掛けとしては、 私は月曜1限系の講義を永遠にさぼり続け、Dを貰うくらいならXを貰ってやるという精神で過ごしてきた結果。 教養科目の単位が足りなくて卒業出来なくなりそうだったから。 出席しないとやばくなり大学に泊まれば遅刻しないじゃん!!ってなって泊まるようになった。
7月
最終的に namazu-tech.hatenablog.com こんな感じで結末を向かえるISUCONに挑戦しようよ-!って言い出して、チーム結成、ちょろっと練習を始めたりした時だった。
Goのお勉強とかをちょろっとしたりしていた。 あとAnsible、Vagrantとかいうのにも初めて触れた。
引き続きHeroku擬きを作っていた。 この時点ではだいぶ良い感じに動くようにはなってきて、フロントの作り込みをしていた。
8月
夏休みシーズンだったか? たぶん大学にずっと泊まっていた。 某所がオタク部屋になり始めたのもこの頃からな気がする。 1週間以上連続で泊まっていた時があったのでこの頃が大学泊の最長記録だったと思う。
ずっとオタク部屋でソフト書いたりしていた。
あと中間発表だったりした。 本番で案の定失敗し、本番に弱い男レッテルを自分で貼った。 生まれてから本番発表が上手くいったためしがない。
引き続きISUCONの練習をちまちましていたけれど、中間発表とかと色々あってなかなか集中出来なかった。 オーバーフロー気味になって多数タスクの並列処理が苦手だなー生まれて初めてと感じた時だった気がする。
毎日小川流とかたたてーとか行きまくったりした結果 太った。
9月
Heroku擬きのCSCへの導入とかいろいろをしていた。 PCを組んだり色々と楽しくやっていた。
たしか3年生の早期配属の子が入ってきたのもこの辺り?で、研究室が賑やかになりはじめた気がする。
10月
ISUCONの予選だったりした。 慌てて練習したりしていた気がする。
3年生がいっぱい研究室に入ってきて、大分賑やかになった気がする。 あれ、こんな狭かったっけなぁってなることが多かった。
11月
ブログを始めた
酔っ払ってTwitterで騒いでたら始めることになった。
なんだかんだちゃんと続いているし、そこそこ楽しいので始めて良かったと思う。
あと、仮想通貨を始めた。
12月
現在進行形で、卒論が、ヤバイ。
まぁ書けばおわる。 どうせブログ20日分くらいでしょ? だから処理出来るはずなんだけど、面倒くさい。
さいご
今年は、フロントを触ってたら、なんか物理ハードを触るようになったり、サーバを触るようになったり色々とやった気がする。 ていうか、ここに書くのがITネタしかないの。 これIT系自分から取ったら何も無いよって事ですよね。 実際にオタクとエンジニアで自分の構成要素99パーセント出来てる感じなのでその通りなのですが。。。
もうすこしなんか、別なこととかあったほうがいいかもなーって。 エンジニアの外に出たら会話が成り立たないですね。
就職とかしたら、とりあえず働いて、家帰ったらなんかまた別のコード書いたりして、寝る。 あとたまにエロゲと同人誌を買いに行く。 っていう生活しかしなさそうです。
せっかくブログとかしてるんだし、なんか別の生産性あることとかしたほうがいいかもしれませんね。
そうして思いついたのが「なんか面白そうなソフトを月一で作る。」これはもうダメ。
アドベントカレンダー明日は@fubukiくんです。 それでは。
田胡研とクリスマスパーティーとLT会
きょうやったこと
停電に合わせてファイルサーバの移行等を一気に行うため、ファイルの移動準備等をしていました。
研究室のクリスマスパーティーでLTをしました。
クリスマスパーティー
今年も研究室ではクリスマスパーティーをしました。
先生がケーキ台を出してくれたり、お金を出してくれるけど頭のおかしい人がLピザをいっぱい頼んだり、ケンタッキーを買ってきてくれたりして、皆でわいわいしました。


とても楽しかったです。
今年はピザを食べながら研究室内でLT会をしました。 みんな色々と個性のある発表で面白かったです。
特に、神のLTを聞く機会があったのがとても良かったです。
私は当初フロントで喋ろうと思ったのですが、あまりフロントとか興味ありそうな人がいない上入門ネタもあまり受けなさそうな感じがしていたので、 一年間サーバとか色々触ってきて微妙に得た知見をまとめて喋りました。
人前で調べるとちょっと恥ずかしそうなコマンド集です。 簡単なコマンドは皆知っているので、あれ?どうやるんだったけなー? 系を集めました。 まぁこれからもわからんコマンドひたすら出てくるのでしょうが、コマンド系はしっかり頭に叩き込んでおきたいです。
スライドは↓
うまく喋れなかったのですが、評価はしてもらえたようで

景品のGoogleHomeMiniを頂きました。
景品購入に2500円出資してHomeMiniを手にしたので費用回収できてよかった。 初のスマートスピーカーなので色々遊んでみたいですね。
LT会の総評や全員の発表まとめとかは、@kiitanが研究室のアドベントカレンダー最終日に書いてくれるそうなので期待。
どうでもいいこと
今日は3年生が研究室にいっぱい来る日で、3年生が今後の目標とかを発表する会をしていました。
私はファイルのコピーが終わらず暇をしていたので、適当に見に行きました。
どうでもいいです&やる気無いです系の発表をする子がいました。 こういう合わなかったかな?系の人は一定確率で紛れ込むのでどうしようもないのですが、 これに真面目にTA勢対応していて色々と感じることがありました。
こういうミスマッチした学生と立場から定型的に対応しないといけないTA。 こういう悲劇なんとかならないんですかねぇ。
私は、ミスマッチしたら集団を分割し、暮らせばいいと思うのだけどどうなんでしょう。 大きな損失が発生する場合ならそうも言っていられないけれど、今回のような場合住み分けてうまくやっていったほうが、総じて幸せだと思います。
基本的に安定する集団を確保するように動き、常にその損失について考えるべき。 というのが私のスタンスです。
業務契約もない関係の人(学生)に教える(強い干渉を行う)って難しいなって改めて感じた一日でした。
それと
ボスからさっさと卒論をせよとの脅しを頂きました。 さすがにやばいので、ちゃんとやろうと思います。
CentOS7 ZECをGPUマイニングする(nvidia)
今日したこと
XMRをマイニングしていたのですが、ネットワークハッシュレートが最近急上昇。 儲けが減ってしましいました。
似たような通貨でありながら、ハッシュレートがまだあまり増えていない感じのZEC(Zcache)のマイニングにシフトしました。
マイナー探しとか意外と手間取ったので紹介しておきます。
前提
- CentOS7バニラ
- GTXの古くないボード
やりかた
- cuda入れる
- zcacheのマイナー導入
- 適当なプールで掘る
cudaインストール
cuda9で動きました。
多分この手順そっくりそのままやれば入ります。
su cd ~ yum update -y yum install -y wget kernel-headers kernel-tools gcc wget https://developer.nvidia.com/compute/cuda/9.1/Prod/local_installers/cuda_9.1.85_387.26_linux -o cuda.run sh cuda.run # なんか立ち上がるので okやaccept連打でいれる # 一度失敗する, リブートを要求されるので dracut -f # これでinitramfsを作り直してからrebootし reboot # もう一度 sh cuda.run
これでインストールができるはず。
Zcacheのマイナー導入
これを使う。 Linux用のビルド済みバイナリが落とせる
マイナーのリストは Zcash Mining Software - Zcash Community ここにあるので選ぶのもいいかも。
mkdir zec cd zec wget https://github.com/nanopool/ewbf-miner/releases/download/v0.3.4b/Zec.miner.0.3.4b.Linux.Bin.tar.gz -O miner.tar.gz tar xzvf miner.tar.gz chmod +x miner
これで利用準備OK
適当なプールで掘る.
minerを解凍したら出てくるstart.shを
./miner --server zec-asia1.nanopool.org --user $address.$worker-name/$email --pass z --port 6666
こんな感じで pool , wallet ,worker, emailを設定.
nanopoolでアジアならサーバはzec-asia1.nanopool.orgがいいかも. japanのサーバなんかやったら繋がらなかった。
ここまでやったら、走らせれば
./start.sh
OK!!
XMRよりレート対儲けが大きい。 さぁ掘るぞー。
どうでもいいはなし
今日はなんか某先生と一緒に大学でWifiのアクセスポイントの強さ測定みたいなのをしていました。 いまは届いていないところに、新規にWifiのアクセスポイントを増やすらしく、どこにアクセスポイントを何個置けばちゃんと通信できるのかーとか色々と測っていました。
アクセスポイントを台車に載せてごろごろ移動したり、測定用PCを持って色々な研究室にお邪魔したりしていました。
わかったことは 弊研究室は(教授部屋以外)そこそこ綺麗 ということです。
美少女ゲームのSS処理ソフトつくった
はじめに
この記事は「TUT 今年もTwitterしかしてませんAdventCalender 2017」の19日目の記事です。 なんかTwitterで見かけて、面白そうだったので枠を取りました。
このカレンダーに乗ってる人の大半を私は知りませんが、枠を取った以上記事を書いていこうと思います。
$whoami
ある程度内輪っぽいところに突っ込んでおいて、自己紹介もしないと「あんただれ?」ってなりそうです。
なので、ちょっとだけパーソナリティを書いておきます。
- CS4年
- 田胡研の鯖缶
- カタケンの11Fにある部屋(昔LinuxClubが追い出された)によくいる(住んでる)
- CSC(クラウドサービスセンター)のサービスを開発したりしている人 (ポータルのことは知ってるけど手を付けてない)
namzu510と書いてますが、私の誕生日は5月10日ではありません。
以上です。しらんがな。って感じですね。
本題に移ります。
エロゲのSS
エロゲ好きな人います? 私は好きです。可愛いやつが好きです。
最近だと白もち桜先生のやつとかがお気に入りです。最近、あのブランド新作が発表されたので期待しています。

ロロログのことねちゃん、かわいいですね。 とってもかわいい。 FDもかわいかった。
私はエロゲをやりながらよくSS(スクリーンショット)を撮ります。

こんな感じのです。 星メモのメアちゃんいいですよね。 バカバカって言われたいです。 たまに一緒に星見をする妄想をしていたりします。
そして撮ったこんな感じの画像を、LINEとか適当なスレとかでスタンプ代わりに貼ります。 そうすると意外と楽しい。
私は今SSを5万枚程持っていますが、これくらいあると大抵の台詞には返せます。
最近のゲームにはおまけ機能としてSSジェネレータがあったりして、任意の台詞をキャラに喋らせることができるわけですが、そういうのは邪道だと思います。
SSの整理
プレイしながらSSを撮っていきどんどんため込むわけですが、これため込んでおいてもどっかに貼り付けようとするとそのままだとかなりキツいです。
なぜかというと
キャラがなんて喋ってるか画像みないと分からないから。
そりゃスクショしただけの画像のタグにキャラの台詞が入ってるわけないですよね。
ということで私は適当にとったSSのファイル名を変更して台詞にするわけです。 そうしておくと検索ソフトで
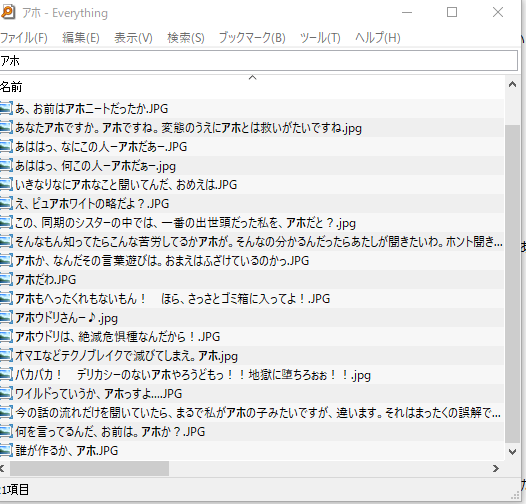
こんな感じに引っ掛かるのでよしなに使えるというわけです。
ひたすらタイピングしてファイル名変えるの飽きた
最初のうちはこれそこそこタイピング練習に有用でした。点丸入ってる文章が多いし、そこそこ長文なので、変換を含めた結構いいタイピング練習になります。
たださすがに飽きました。そこそこの速度がタイピングで出せるようになったし。もういいかなって感じます。
OCRしてファイル名いじればそれでよくね?
ほんとうにそれでいいので、なんか楽にできる方法ないかなって探りました。 ディレクトリの中に同じゲームのスクショが500枚くらいあります、その台詞領域に対してOCRしてくれて、実行結果でファイル名を返してくれればいい。
なんかいい感じのがなかったから作った
適当に探してもいい感じのが見つからなかったので適当に作りました。(結構昔に)
jsで走らせられるOCRがあったのでそれを利用
Tesseract.js | Pure Javascript OCR for 62 Languages!
これです。 これを利用してElectronでアプリを作りました。 フレームワークはVue.jsです。 結構昔(10カ月くらい前?)に途中まで作って放り出しておいて、今回のカレンダーでちゃんと動くようにしようと思って頑張った。
結果

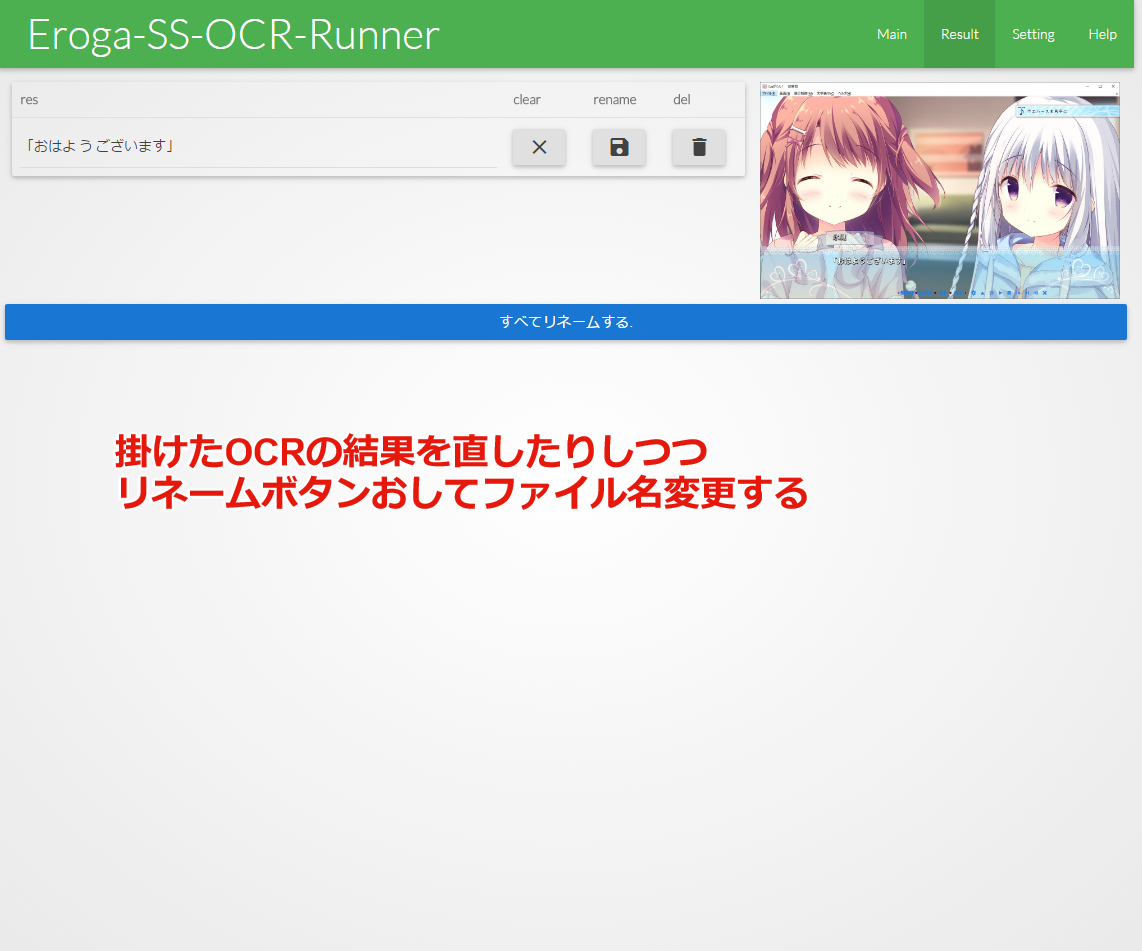
こんな感じで使えます。
一々全部をタイピングしていくのと比べれば相当楽になりました。 プレイしおわったら、ウィンドウ枠を別の画像一括編集ツールで削り、このソフトに通してリネームします。
これで台詞を簡単にファイル名にすることができ、いい感じにSSを整理できるようになりました。
課題とか
OCRがショボい
フリーで落としてきて、しかもjsで動く分にはいいかなぁだけど、フォントとかによりOCR結果が厳しくなる。
- 二値化
- 画像の拡大
このへんはやってみました。 そこそこ効果ある(二値化しないとまともに動かなかった)
ただまぁフリーなぶんしょうがないかなぁ感? 私はでいぷらの人ではないので高機能なOCRを用意しようとしても無理。
なのでGoogleのAPIを使ったりしようかと、ただあれ大量に投げつけるとお金かかるからねぇ。 その辺無料枠でやりくりするようにしないといけない。 ただこの対応はすぐできると思うのでやりたい。
くそ設計でぐっちゃぐちゃ
エレクトロンのアプリを超適当に作ると闇を抱えることを知りました。 まぁそんな拡張するつもりのアプリではないので、リファクタする気はないですが、今後エレクトロンのアプリ作るときはしっかり考えたいです。
さいご
ネタが思いつかなかったので、昔につくりかけたソフトをある程度動くようにして、ネタにしました。 今になって考えると、大学に住むHowtoとか、大学の某所を勝手にオタク部屋にした話とかでもよかったかもしれない。
こんなくそみたいなソフト作ったところで技術力上がるわけないけど、オタク的欲望をソフトウェア開発の原動力にするのは大変よろしい。 まず第一にやる気が出ないと何もやらないのでね。。。。。
「TUT今年もTwitterしかしてません アドベントカレンダー」明日は @pana_pana_kuma さんです。